DIET Cloud and Nimbus
In all scientific domains, workflows are a common application pattern. Orchestrating a large-scale experiment is currently a complex and time consuming task on a traditional shared platform like a grid. Scientist have to compete with each other for compute resources. This imposes a hard limit on the number of large scale experiments that can be performed and thus on the
evolution of the comunity itself. It is also worth noting that fixed size reservation-based grid platforms lead to overbooking and underuse of resources. With on-demand resources and smarter resource allocation algorithms one could achieve a larger experiment throughput, more efficient resource usage and lower experimentation overhead.
The purpose of the current showcase is to demonstrate how DIET Cloud can allows scientists to outsource their workflow experiments to IaaS Clouds. Our approach is to determine budget-constrained on-demand resource allocations especially tailored for each application and the resource catalog offered by the IaaS Cloud.
For this demonstration we have used the RAMSES workflow application. It is an Adaptive Mesh Refinement (AMR) application with the goal of simulating a region of space starting from initial conditions until reaching the formation of galaxies. It can refine
the simulation in certain regions of interest called ”zoom regions”. One possible improvement for this and many other workflow applications is in the direction of ease of use and reducing the experimentation overhead. We will also show a demo use-case and preliminary results on running the system on the FutureGrid testbed with a Nimbus IaaS Cloud deployment and the RAMSES test application.
DIET/Nimbus architecture
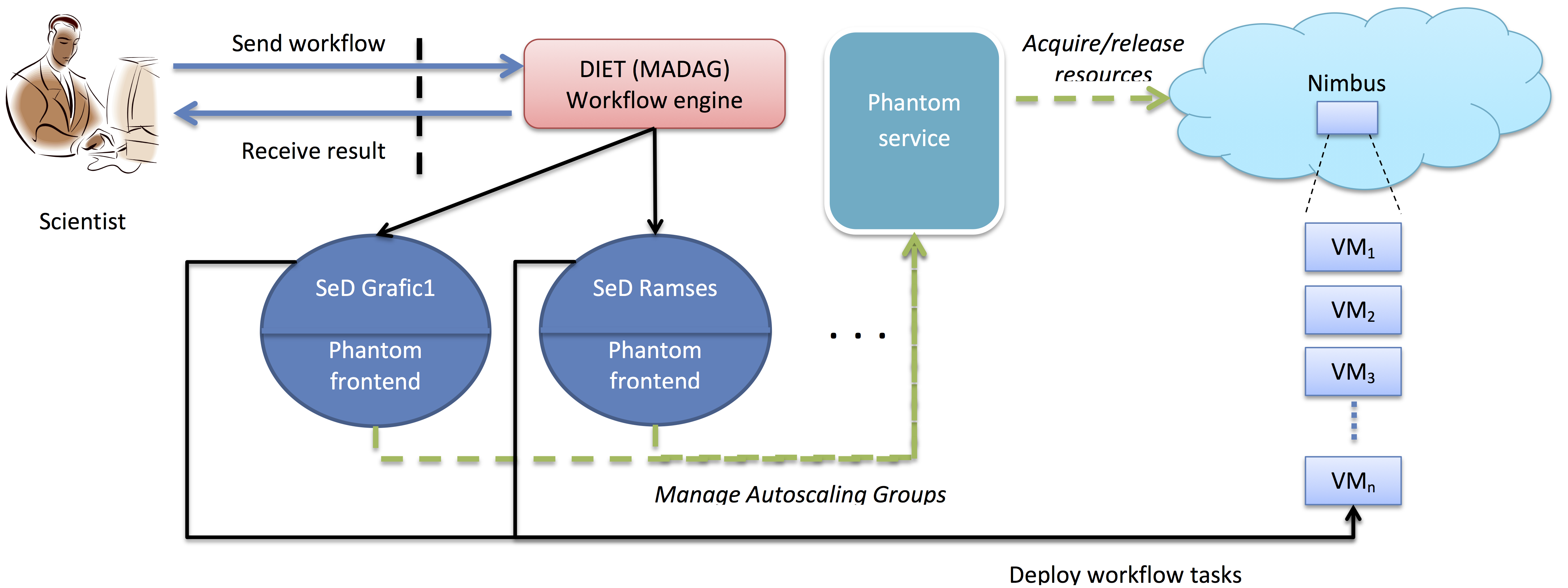
DIET/Nimbus architecture
The architecture that we have proposed for this demo has the following main components described below.MADag (DIET)
The MADag is a workflow engine developed as part of the DIET toolkit. It supports simple DAG workflows, Parallel Task Graphs (PTG) and functional workflows through the Gwendia language. In the current scenario we have used one task per DIET service to implement the workflow’s functionality.
Nimbus
Nimbus is an open source IaaS Cloud software stack. It is compatible with the Amazon EC2 IaaS interface. In the current scenario we have used Nimbus as a low level resource provider, via a FutureGrid installation.
Phantom
Phantom is an open source auto-scaling service built as part of the Nimbus platform. It implements a part of the Amazon auto-scaling service interface. We have used it as a high level resource provider.
Client
The platform client describes his workflow in an XML form and implements the workflow’s tasks as DIET services. Next, the client invokes the workflow engine, passing his XML description and the workflow execution is done automatically. Throughout the process of running the workflow application, the client does no explicit resource management.
Experimental result
We have experimented with various runs of the RAMSES application. We have tested two types of resource provisioning approaches: static preallocations of the resources and dynamical allocations that allocate new resources on-demand and release existing ones when they are not used.
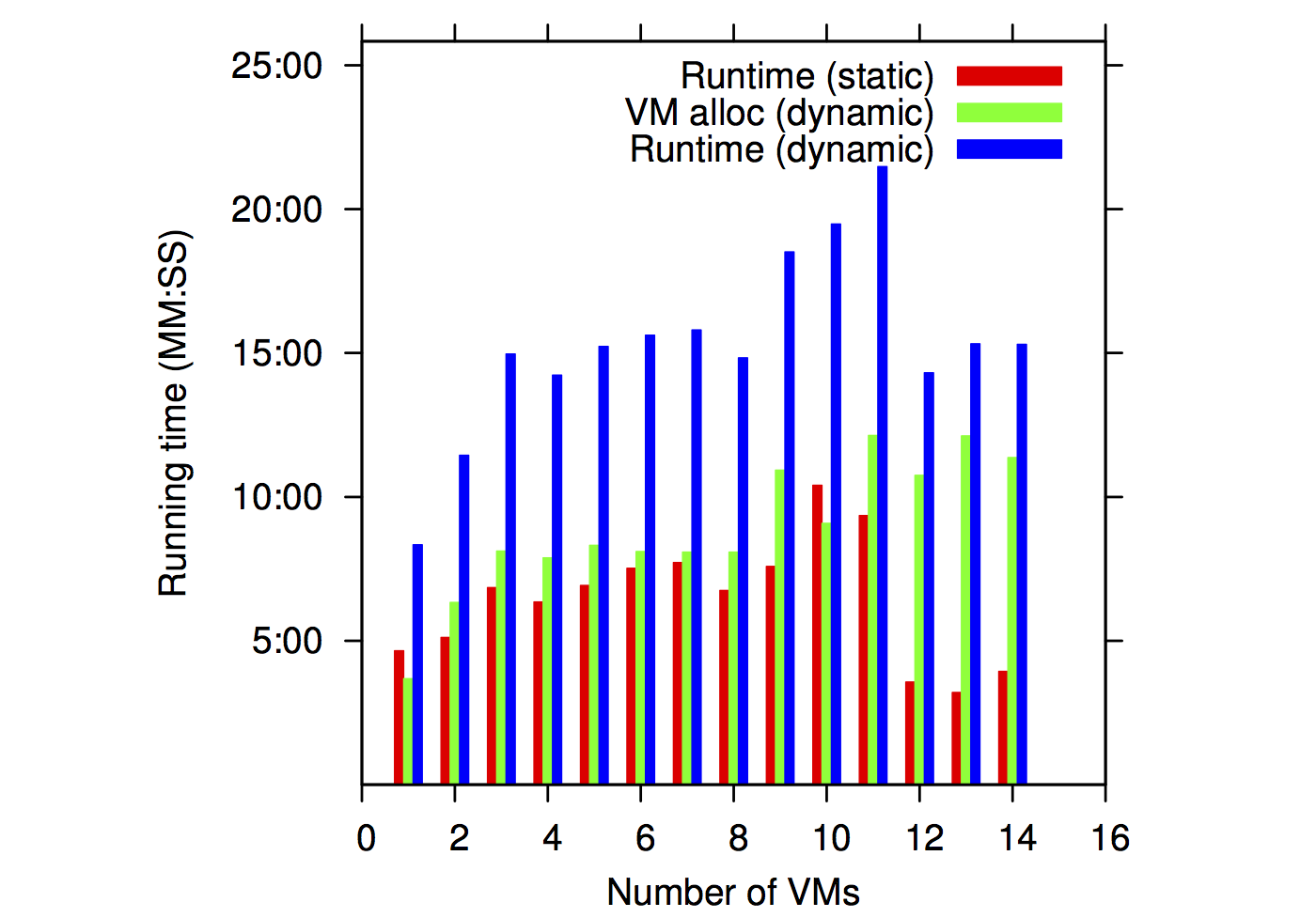 Running times for static and dynamic allocations |
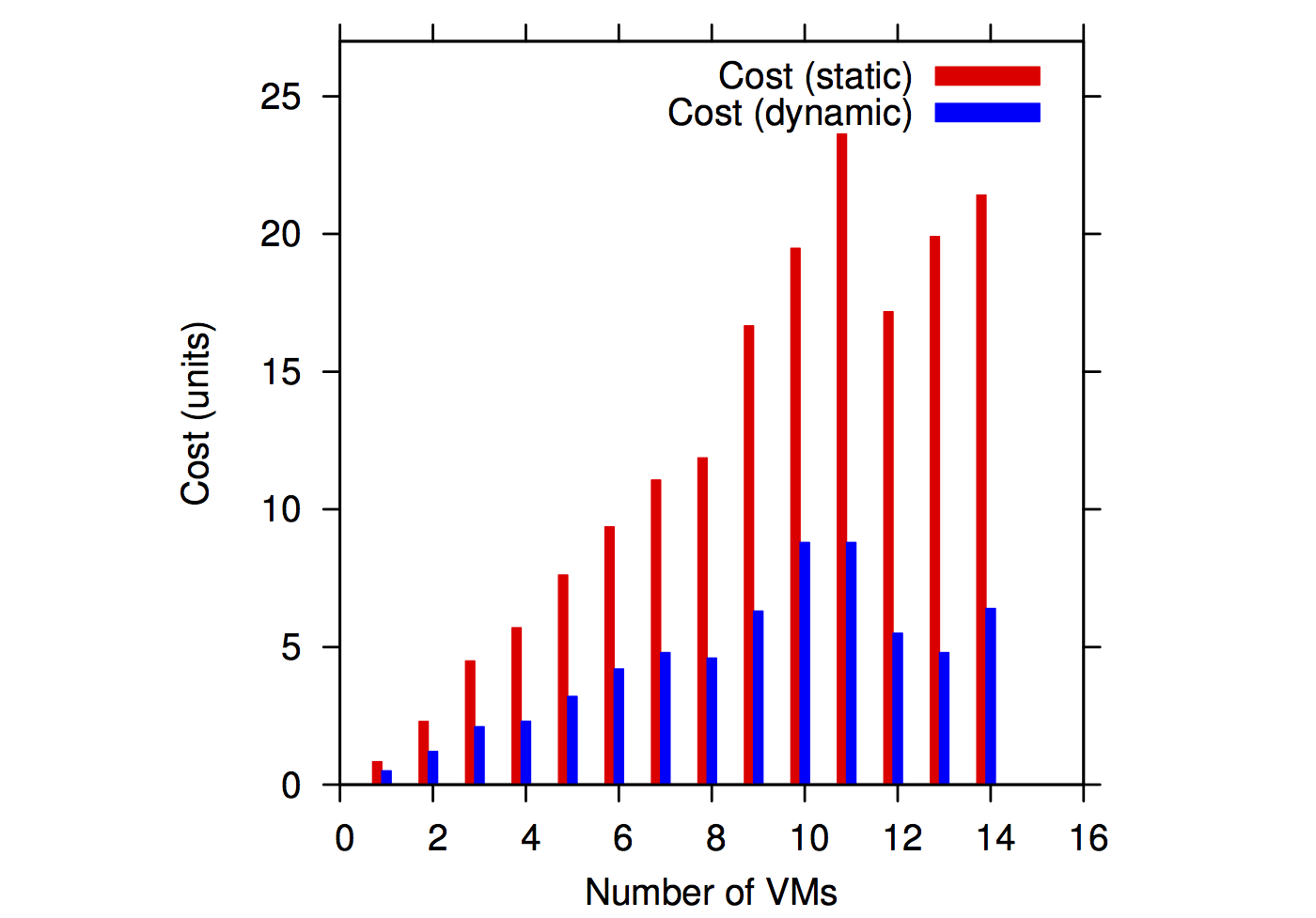 Cost estimations for static and dynamic allocations |
From the point of view of running times, the static allocations result in faster executions because all the resources are available when they are needed. Dynamic allocations have to pay for a VM reallocation time (highlighted in green in the above plots). An important observation for this scenario is that the VM allocation time tends to stabilize after a while, becoming constant. In essence, VM allocation time becomes a constant overhead.
On the other hand, when related to cost estimations, the dynamic platform clearly outperforms the static one by a factor of as much as 4x in the case of the RAMSES application.
The take-away conclusion is that dynamic IaaS platforms can improve the cost efficiency of workflow applications if the applications have a non-constant demand of resources.