Next: The DAGDA configuration options Up: DAGDA: Data Manager Previous: DAGDA: Data Manager Contents
DAGDA allows data explicit or implicit replications and advanced data management on the grid. It was designed to be backward compatible with previously developed applications for DIET which benefit transparently of the data replications. Moreover, DAGDA limits the data size loaded in memory to a user-fixed value and avoids CORBA errors when transmitting too large data regarding to the ORB configuration.
DAGDA offers a new way to manage the data on DIET. The API allows the application developer to replicate, move, add or delete a data to be reused later or by another application. Each component of DIET can interact with DAGDA and the data manipulation can be done from a client application, a server or an agent through a plug-in scheduler.
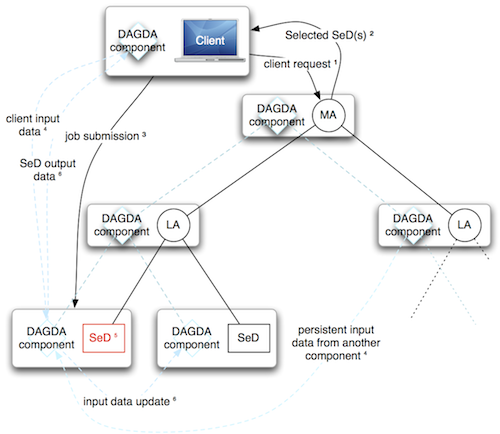
A DAGDA component is associated to each element in a DIET platform (client, Master Agent, Local Agent, SeD). These components are connected following the DIET deployment topology. Figure 16.1 shows how the DAGDA and DIET classical components are connected. Contrary to a DIET architecture, each DAGDA component has the same role. It can store, transfer or move a data. The client's DAGDA component is isolated of the architecture and communicates only with the chosen SeDs DAGDA components when necessary. When searching for a data, DAGDA uses its hierarchical topology to contact the data managers. Among the data managers having one replicate of the data, DAGDA chooses the “best” source to transfer it. To make this choice DAGDA uses some statistics collected from previous data transfers between the nodes. By not using dynamic information, it is unsure that DAGDA really chose the “best” nodes for the transfers. In a future version, we will introduce some facilities to estimate the time needed to transfer a data and to improve the choice of a data stored on the grid. To do the data transfers, DAGDA uses the pull model: it is the destination node that asks for the data transfer.
Figure 16.1 presents how DAGDA manages the data when a client submit a job. In this example, the client wants to use some data stored on the grid and some personal data. He wants to obtain some results and to store some others on the grid. Some of these output data are already stored on the platform and they should be updated after the job execution.