Two applications in this field used DIET:
1. About Astrophysics and Cosmology
1.1 Astrophysics
source Wikipedia
Astrophysics (Latin: Astronomus – meaning « space », Greek: physis – meaning « nature ») is the branch of astronomy that deals with the physics of the universe, including the physical properties (luminosity, density, temperature, and chemical composition) of celestial objects such as galaxies, stars, planets, exoplanets, and the interstellar medium, as well as their interactions. The study of cosmology is theoretical astrophysics at scales much larger than the size of particular gravitationally-bound objects in the universe.
Because astrophysics is a very broad subject, astrophysicists typically apply many disciplines of physics, including cosmology, mechanics, electromagnetism, statistical mechanics, thermodynamics, quantum mechanics, relativity, nuclear and particle physics, and atomic and molecular physics. In practice, modern astronomical research involves a substantial amount of physics. The name of a university’s department (« astrophysics » or « astronomy ») often has to do more with the department’s history than with the contents of the programs. Astrophysics can be studied at the bachelors, masters, and Ph.D. levels in aerospace engineering, physics, or astronomy departments at many universities.
(This article is licensed under the GNU Free Documentation License. It uses material from the Wikipedia article « Astrophysics ».)
1.2 Cosmology
source Wikipedia
Cosmology (from Greek kosmos, « universe »; and logia, « study ») is study of the Universe in its totality, and by extension, humanity’s place in it. Though the word cosmology is recent (first used in 1730 in Christian Wolff’s Cosmologia Generalis), study of the Universe has a long history involving science, philosophy, esotericism, and religion.
2. RAMSES
| partners / contributors | ||
|---|---|---|
| Hélène Courtois | CRAL, Observatoire de Lyon | |
| Romain Teyssier | Service d’Astrophysique CEA | |
RAMSES is a typical computational intensive application used by astrophysicists to study the formation of galaxies. RAMSES is used, among other things, to simulate the evolution of a collisionless, self-gravitating fluid called « dark matter » through cosmic time. Individual trajectories of macro-particles are integrated using a state-of-the-art » N body solver « , coupled to a finite volume Euler solver, based on the Adaptive Mesh Refinement technics. The computational space is decomposed among the available processors using a mesh partitionning strategy based on the Peano–Hilbert cell ordering. Cosmological simulations are usually divided into two main categories. Large scale periodic boxes requiring massively parallel computers are performed on very long elapsed time (usually several months). The second category stands for much faster small scale « zoom simulations ». One of the particularity of the HORIZON project is that it allows the re-simulation of some areas of interest for astronomers.
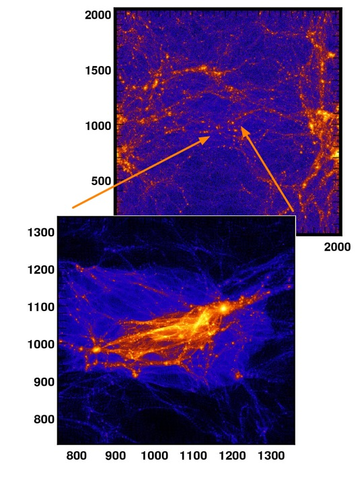
Figure 1: Re-simulation on a supercluster of galaxies to increase the resolution
For example in Figure 1, a supercluster of galaxies has been chosen to be re-simulated at a higher resolution (highest number of particules) taking the initial information and the boundary conditions from the larger box (of lower resolution). This is the latter category we are interested in.

Figure 2: Time sequence (from left to right) of the projected density field in a cosmological simulation (large scale periodic box).
Performing a zoom simulation requires two steps: the first step consists of using RAMSES on a low resolution set of initial conditions i.e. with a small number of particles) to obtain at the end of the simulation a catalog of « dark matter halos », seen in Figure 2 as high-density peaks, containing each halo position, mass and velocity. A small region is selected around each halo of the catalog, for which we can start the second step of the « zoom » method. This idea is to resimulate this specific halo at a much better resolution. For that, we add in the Lagrangian volume of the chosen halo a lot more particles, in order to obtain more accurate results. Similar « zoom simulations » are performed in parallel for each entry of the halo catalog and represent the main resource consuming part of the project.RAMSES simulations are started from specific initial conditions, containing the initial particle masses, positions and velocities. These initial conditions are read from Fortran binary files, generated using a modified version of the Grafic code. This application generates Gaussian random fields at different resolution levels, consistent with current observational data obtained by the WMAP satellite observing the cosmic microwave background radiation. Two types of initial conditions can be generated with Grafic:
- Single level: this is the « standard » way of generating initial conditions. The resulting files are used to perform the first,low-resolution simulation, from which the halo catalog is extracted.
- Multiple levels: this initial conditions are used for the « zoom simulation » The resulting files consist of multiple, nested boxes of smaller and smaller dimensions, as for Russian dolls. The smallest box is centered around the halo region, for which we have locally a very high accuracy thanks to a much larger number of particles.
The result of the simulation is a set of « snaphots ». Given a list of time steps (or expansion factor), RAMSES outputs the current state of the universe (i.e. the different parameters of each particules) in Fortran binary files.
These files need post-processing with Galics softwares: HaloMaker, TreeMaker and GalaxyMaker. These three softwares are meant to be used sequentially, each of them producing different kinds of information:
- HaloMaker: detects dark matter halos present in RAMSES output files, and creates a catalog of halos
- TreeMaker: given the catalog of halos, TreeMaker builds a merger tree: it follows the position, the mass, the velocity of the different particules present in the halos through cosmic time
- GalaxyMaker: applies a semi-analytical model to the results of TreeMaker to form galaxies, and creates a catalog of galaxies
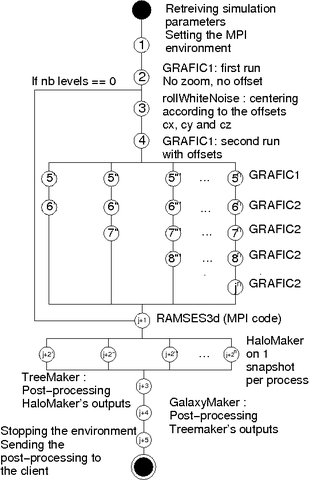
Figure 3: workflow of the simulationFigure 3 shows the sequence of softwares used to realise a whole simulation.
Grid’5000 is the French Research Grid. It is composed of 9 sites spread all over France, each with 100 to 1000 PCs, connected by the RENATER Education and Research Network (1Gb/s or 10Gb/s). For our experiments, we deployed a DIET platform on 5 sites (6 clusters).
- 1 MA deployed on a single node, along with omniORB, the monitoring tools, and the client
- 6 LA: one per cluster (2 in Lyon, and 1 in Lille, Nancy, Toulouse and Sophia)
- 11 SEDs: two per cluster (one cluster of Lyon had only one SeD due to reservation restrictions), each controlling 16 machines (AMD Opterons 246, 248, 250, 252 and 275)
We studied the possibility of computing a lot of low-resolution simulations. The client requests a 128^3 particles 100Mpc.h^-1 simulation (first part). When it receives the results, it requests simultaneously 100 sub-simulations (second part). As each server cannot compute more than one simulation at the same time, we won’t be able to have more than 11 parallel computations at the same time.
The experiment (including both the first and the second part of the simulation) lasted 16h 18min 43s (1h 15min 11s for the first part and an average of 1h 24min 1s for the second part).
The benefit of running the simulation in parallel on different clusters is clearly visible: it would take more than 141h to run the 101 simulation sequentially.
Website:
License type:
CeCILL.
The needs:
- Language(s):Fortran 90, C/C++ for the client and servers
- Compiler(s):gfortran, gcc
- Library(ies):In case of parallel computations : mpi
- System(s):Linux, Unix
- Memory:For a 128^3 particles 100Mpc.h^-1 simulation : 2GB.
- Disk:For a 128^3 particles 100Mpc.h^-1 simulation : between 26 GB and … depending on the number of backups
- Mean execution time:For a 128^3 particles 100Mpc.h^-1 simulation : around 1h15 for the first part and around 1h20 for the second part.
- Number of processors:
- Minimum: 1
- Maximum: 5000
- Use of a Database:No.
- Other specific needs:NFS partition to store files
3. GalaxyMaker & MoMAF
| partners / contributors | ||
|---|---|---|
| Jeremy Blaizot | CRAL, Observatoire de Lyon |
Simulations are often used in astrophysics to validate models. However, such models, like the one describing galaxies formation, rely on a set of parameters one has to tune so as to fit observational data. Thus, in order to find the best set, or the best sets of parameters, we need to compare the result of the model with real observational data. Hence, we need to run simulations with as many sets of parameters as possible to build catalogues of galaxies, build mock observational data, and compare them to real data obtained using real instruments. This is the aim of the two following software: GalaxyMaker and MoMaF.
Galics is a hybrid model for hierarchical galaxy formation studies, combining the outputs of large cosmological N-body simulations with simple, semi-analytic recipes to describe the fate of the baryons within dark matter halos. The simulations produce a detailed merging tree for the dark matter halos including complete knowledge of the statistical properties arising from the gravitational forces. GalaxyMaker, is one the software composing Galics, it applies a semi-analytical model to form galaxies, and create catalogues of galaxies.
MoMaF converts theoretical outputs of hierarchical galaxy formation models into catalogues of virtual observations. The general principle is straightforward: mock observing cones can be generated using semi-analytically post-processed snapshots of cosmological N-body simulations. These cones can then be projected to synthesize mock sky images.
A typical simulation is composed of the following workflow, we need to run it for each input parameters set we wish to analyse:
- Run GalaxyMaker on one or many input files (typically a hundred files).
- All the produced outputs are merged, and then post-processed using MoMaF. An instance of MoMaF is necessary for each parameter set for each line of sight (typically around a hundred).
The following figure depicts the workflow.
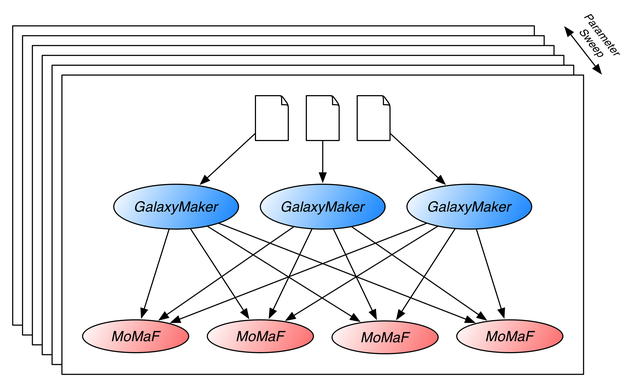
Figure 1: GalaxyMaker and MoMaF wokflow
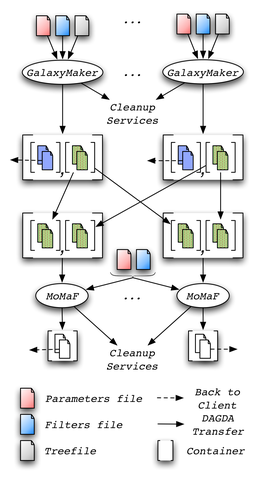
Figure 2: GalaxyMaker and MoMaF wokflow with DIET data management
Execution of this workflow is available through a web portal. It has been developed using the DIETWebboard, a tool for online management of DIET services and requests. The website allows for parameter sweep submissions, and takes care of data management. Within DIET, the MA DAG, i.e. a special agent in charge of scheduling workflow tasks, handles tasks management. Data management is handled by DAGDA: all generated files are stored inside containers, and dynamically created cleanup services take care of platform integrity and cleanup once a workflow is finished. The following figure presents a more detailed view of a workflow execution.
Website:
License type:
Not distributed.
The needs:
- Language(s): Fortran 90, C/C++ for the client and servers
- Compiler(s): PGF90, iFort, gnufortran, gcc
- Library(ies): none
- System(s): Linux
- Memory: Up to 2 GB.
- Disk: From a few MB to hundreds of GB
- Mean execution time: From a few seconds to several days.
- Number of processors: This is a sequential application
- Use of a Database: No.