| Partners / Contributors | ||
|---|---|---|
| Gaël Le Mahec | MIS (Université de Picardie Jules Verne) | |
| Vincent Breton | IN2P3 | |
DAGDA: Data Arrangement for Grid and Distributed Application
DAGDA is now the data manager by default for the DIET middleware which allows data explicit or implicit replications and advanced data management on the grid. It was designed to be backward compatible with previously developed applications for DIET which benefit transparently of the data replications. DAGDA introduces some new data management features in DIET:
- Explicit or implicit data replications.
- A data status backup/restoration system.
- File sharing between the nodes which can access to the same disk partition.
- Choice of a data replacement algorithm.
- High level configuration about the memory and disk space DIET should use for the data storage and transfers.
DAGDA transfer model
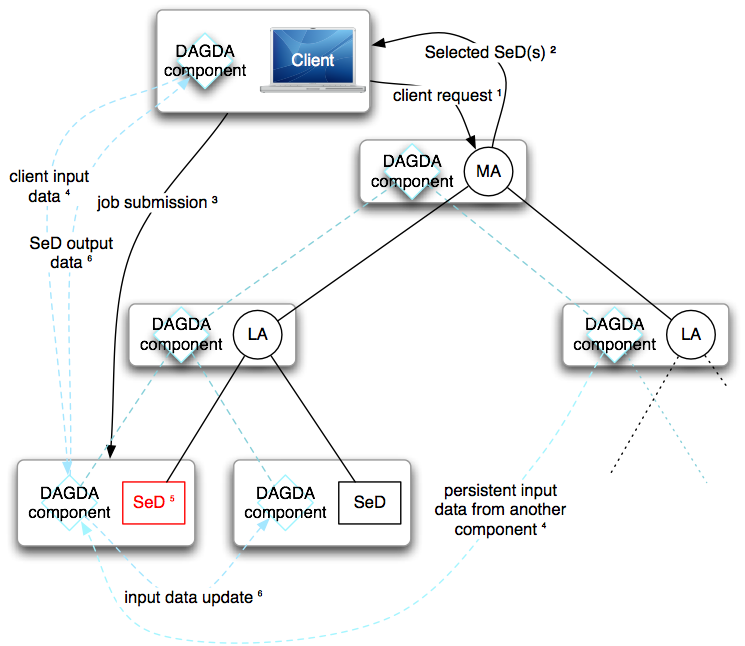
Figure 1: DAGDA Architecture
To transfer a data, DAGDA uses the pull model instead of the push model used by DTM: The data are not sent into the profile from the source to the destination, but they are downloaded by the destination from the source. Figure 1 presents how DAGDA manages the data transfers for a standard DIET call:
- The client performs a DIET service call.
- DIET selects one or more SeDs to execute the service.
- The client submits its request to the selected SeD, sending only the data descriptions.
- The SeD downloads the new data from the client and the persistent ones from the nodes on which they are stored.
- The SeD executes the service using the input data.
- The SeD performs updates on the inout and out data and sends their descriptions to the client. The client then downloads the volatile and persistent return data.
At each step of the submission, the transfers are allways launched by the destination node. All the transfers operations are transparently performed and the user does not have to modify its application which uses data persistency to take benefits of the data replications.
Remark: After the call, the persistent output data obtained from other nodes are replicated on the SeD and will stay on it until they are erased by the user or by the data replacement algorithm.
DAGDA architecture
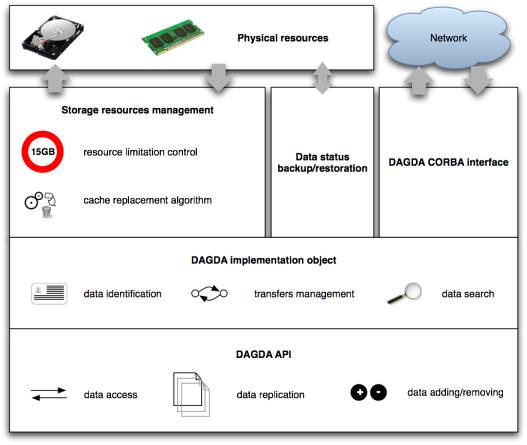
Figure 2: DAGDA Overview
- The DAGDA object associates an ID to each stored data, manages the transfers by choosing the « best » data source according to statistics about the previous transfers time and performs the data searches.
- The CORBA interface is used for inter-nodes communications.
- The storage resources management ensures that the data never exceed the size allowed by the user and replace a data when necessary.
- The DAGDA API allows the user to perform some data management tasks:
- To add a data into the DAGDA hierarchy.
- To get a data from the DAGDA hierarchy.
- To replicate a data on chosen nodes.
Currently DAGDA offers three data replacement algorithms: Least Recently Used (LRU), Least Frequently Used (LFU) and First In First Out (FIFO) :
- LRU: The least recently used data is removed to free the needed space for the new one.
- LFU: The least frequently used data is removed to free the needed space.
- FIFO: The « oldest » data is removed to free the needed space.
These algorithms select the data to be removed only among the non-sticky ones of sufficient size to store the new data.
Interface with DIET
DAGDA is designed to be backward compatible with the previous DIET client-server applications. Moreover, DAGDA extends the standard DIET API with new data management functions. A DAGDA object is interfaced with DIET at each level of the DIET hierarchy.
DAGDA interactions with a client application
- Without performing any change on a previous application that was running with DTM. When the service is called, DIET adds the user data in the client DAGDA component and sends the profile description only.
- Using the API, no service call is needed to manage the data. The user can add a data, replicate a persistent data already in the DAGDA hierarchy or get a data using direct calls to DAGDA.
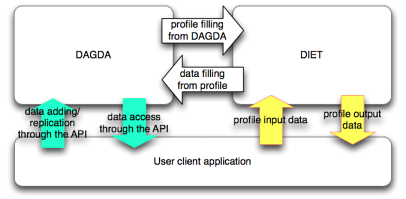
Figure 3: DAGDA Client
DAGDA interactions with a server application.
- Using a simple service call, DIET gets the data from the server DAGDA component. Then DAGDA transfers the data from the client or from a selected source among the DAGDA nodes. The profile is then filled with references to the data and the server developer can use them transparently.
- Using the API, the user can add a data, replicate a persistent data already in the DAGDA hierarchy or get a data using direct calls to DAGDA.
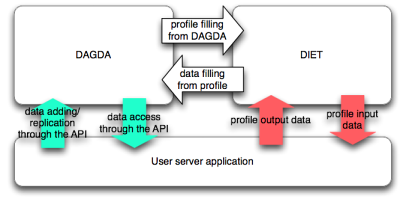
Figure 4: DAGDA SeD
DAGDA interactions with a DIET agent.
- As in the other elements of the DIET hierarchy, the scheduler developer can add a data, replicate a persistent data already in the DAGDA hierarchy or get a data using direct calls to DAGDA.
All the data management function of the API can be used synchronously or asynchronously. For the server and scheduler sides, the tranfers can also be done asynchronously without waiting for their ends.
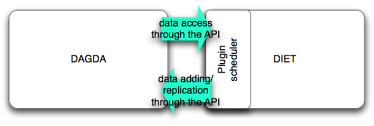
Figure 5: Agent DAGDA
Data Replication
DAGDA allows the users to replicate the data stored on the platform for performance improvements. To select the nodes where the data should be replicated, the replication function takes a replication rule as a parameter. This string is constructed as follows:
- The node identifier to use for the node selection: ID or hostname.
- A string that can use wildcard characters for a glob-like pattern matching.
- A keyword to choose whether DAGDA should remove a data using the data replacement algorithm if necessary: replace or noreplace.
These three parameters have to be separated by the « : » delimiter character. For example, « hostname:*-??.lyon.grid5000.fr:noreplace » is a valid replication rule string which means that the data should be replicated on all the nodes having a hostname matching *-??.lyon.grid5000.fr without removing a data if the free space is not sufficient.
File sharing
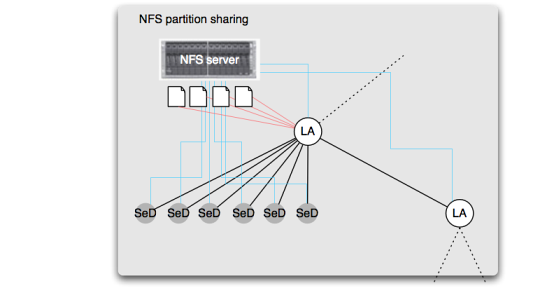
Figure 6: DAGDA file sharing
It is frequent that several nodes can access a shared disk partition (through a NFS server on a cluster for example). With DAGDA, a node can be configured to share the files that it manages with all its children nodes. A typical example of the usage of these features is for a service using a large file as read-only parameter executed on several SeD located on the same cluster. Figure 6 presents such a file sharing between several nodes:
- Two Local Agents and six SeDs can access to the same NFS partition (blue lines).
- The files registered on the first LA (red lines) are declared as shared with all of its children.
- If one of the SeDs or the second LA has to access to one of the files registered on the first LA, they can access it directly without data transfer through DIET.
Status backup/restoration
The user can configure the SeDs and Agents to store their data on a selected file. Then the client can command to all the nodes that allow it to save their current data status. These nodes can then be stopped and restarted restoring their data status. This command allows the user to stop temporary DIET preserving the data status of the chosen nodes after restart.
Physical resources usage configuration
The users can fix several parameters about the resources DAGDA is allowed to use:
- The maximum disk space DAGDA can use to store files.
- The maximum memory space DAGDA can use to store data on memory.
- The maximum CORBA message size DAGDA can send on the network.
All these parameters are optionnal. If the maximum CORBA message size exceeds the maximum GIOP size allowed by the ORB, DAGDA uses this last value avoiding CORBA errors that could occur when using DTM. This default behaviour avoids the users to modify the ORB configuration. DAGDA performs the data transfers in several parts if necessary, so sending a data larger than the maximum CORBA message does not cause any error. Moreover, the measured overhead caused by this behaviour is negligible if the maximum message size is larger than some kilobytes.
Contact
Questions about DAGDA can be directed to diet-usr@liste.ens-lyon.fr or to Gael Le Mahec