Fault Tolerance and Task Migration in DIET
Grids are composed of many geographically distributed resources, each having its own administrative domain. These resources are gathered using a WAN or even Internet. Those characteristics lead Grids to be more error prone than other computing environments. GridRPC is a commonly adopted programming model for Grids and implemented in NetSolve, Ninf or DIET. In this section we detail DIET mechanisms to tolerate failures considering the decentralized design of DIET : fault detection, MA and LA topology recovery, checkpoint/restart based recovery and task migration.
Fault detection
Most common failure scenarios include intermittent network failure between sites and node crash. When considering unreliable network, fault detection is a major issue to ensure application correctness. Failure detectors can be classified considering two criteria: time to detect a failure and accuracy. Detection time represents time between failure and definitive suspicion by the failure detector. Accuracy is the probability of a correct answer of the failure detector when queried at random time. Classical failure detection systems, like TCP, are based on heartbeats and timeouts. Maximum time to detect a failure depends both on the arrival date of previous heartbeat and on the maximum delivery time. Considering a WAN or larger network, maximum delivery time is hard to bound, leading to a tradeoff between long failure detection time and poor accuracy.
In DIET is implemented the Chandra and Toueg and Aguilera failure detector. Considering a given heartbeat frequency and maximal time to detect a failure, this detector has optimal accuracy. Another benefit of this fault detector is its ability to adapt to detected network parameters and reconfigure itself according to changing network delay or message loss probability. To our knowledge, this is the first implementation of this algorithm.
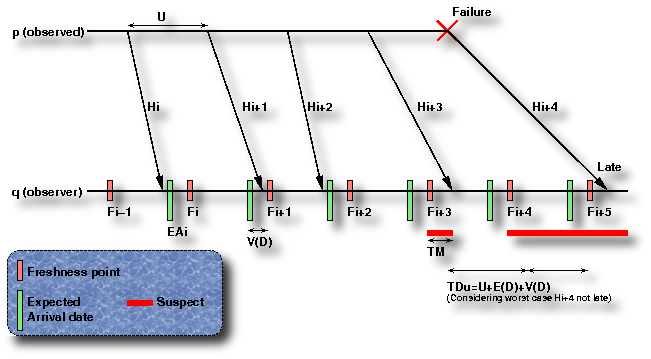
Figure 1: DIET Fault Tolerance mechanism
Parameters of the detector are the expected quality of service, namely TDu the upper bound on time to detect a failure, TMu upper bound on average mistake duration, and TMRl the lower bound on average mistake recurrence time. Observed process sends heartbeats to observer at rate U. The detector suspects the observed process when heartbeat Hi has not been received at date Fi, called a freshness point. As freshness point Fi+1 does not depends on reception date of heartbeat Hi, Fi+1 has to be set considering network parameters and expected QoS. Considering a large enough sample of previous heartbeats are computed EAi the expected arrival date of heartbeat Hi the message delay, V(D) the variance of message delay, and Pl the probability of a message to be lost. From those values are computed the heartbeat period U and the estimated arrival date of each heartbeat on q (considering q’s local clock). The variance is added to the estimated arrival date to set Fi+1. When network parameters are changing, observing process may reconfigure heartbeat period and compute new EAi to still satisfy QoS under those new constraints.
DIET FD is a part of the DIET library included in both client and server part. There is no centralized fault detector : each client is in charge of observing servers running its own RPC calls. Each observed server costs 750B on the client. As most computation is triggered by the reception of a heartbeat, and typical heartbeat period is less than one heartbeat per 5s, the computational cost per observed service is marginal. Heartbeats are very small UDP messages (40 bytes including UDP headers), thus impact on network of the fault detection service is small.
DIET FD is connected to DIET LogService and VizDIET and may be used to collect statistic about network parameters and Grid reliability.
MA topology recovery
Compared to other GridRPC, DIET uses a decentralized hierarchical infrastructure. Master Agents and Local Agents are organized along a tree topology. When a failure hits an agent the three is split, thus some alive services are no more available to clients.
During normal operation, each agents keeps a list of its nearest ancestors in the three, and observes its father. When the agent detects the failure of its father, it tries to reconnect to the nearest alive ancestor. This algorithm ensures that considering node crash or definitive network disconnection failures, and existence of long enough failure free time slices, every alive agent is connected to a three, even when f-1 simultaneous failures occurs.
Checkpoint/restart mechanism
Unexpectedly, the most intrusive failures are not those hitting infrastructure such as MA/LA but computing nodes. This is mainly due to the large amount of computation time lost. Process replication and process checkpointing are two well known techniques to decrease the amount of lost computation in case of failure. In replication scheme, the same program is running on several hosts. Any input of the program is broadcasted to all the replicas. When a failure arises on the main process, one of the replicas is promoted as the main process. When a failure hits a replica, another replica is created. Thus, having f replicas is sufficient to tolerate f-1 simultaneous failures, but divides the available computing power by f. Checkpoint based fault tolerance relies on taking periodic snapshot of the state of a process, saving it to another (safe) place. In case of a failure, the process state is recovered from the checkpoint. To avoid dividing the computing power of the platform we choose to use checkpoints to periodically save progression of the services.
DIET services are managed by a SeD on each platform. The SeD offers two different ways to interact with DIET checkpoint :
- Service provided checkpoint : the service includes its own checkpoint mechanisms. It just have to register some files to be included to the DIET checkpoint, and notify DIET when these files are ready to be stored.
- Automatic checkpoint : the service has no provided checkpoint capabilities. Then it is linked with a checkpoint library (such as the Condor Standalone Checkpoint Library). The SeD automatically manages to periodically checkpoint the service.
Checkpoint data are stored on computing resources using JuxMEM. JuxMEM uses data replication to ensure data persistence over failures.
Each client is in charge of observing the RPC it has initiated. When a client detects a failure, it gets a new compatible SeD from the MA, and issue a restart command on this SeD. The SeD then retrieve checkpoint data from persistent data storage and restarts.
Checkpoint aims to faster recover from failures, but it can also be used to move some computing process from nodes to nodes (having compatible architecture). This feature enables to use advanced scheduling algorithms such as moving process from a slow node to a faster one as soon as it becomes available. Moreover, most scheduling algorithms are relying on predictive performances of the platform. When the effective performance does not match the prediction, checkpointing allows to correct the scheduling accordingly to actually measured performance.